Analysis & Predictive Modelling Compounds for Studying Environmental Exposures (PubMed)
EDA
PYTHON
LINER REGRESSION
rdkit
Data Source : Kaggle https://www.kaggle.com/datasets/thedevastator/pubchemlite-compound-collection-for-exposomics-3
Exploratory Data Analysis (EDA):
Visualize distribution of compounds based on PubMed_Count and Patent_Count
Identify most common MolecularFormula and SMILES structures
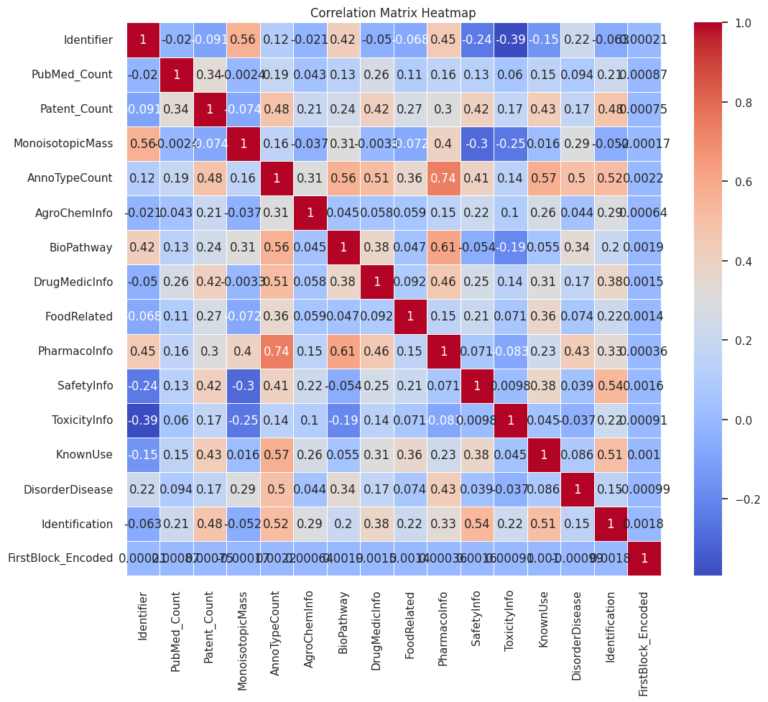
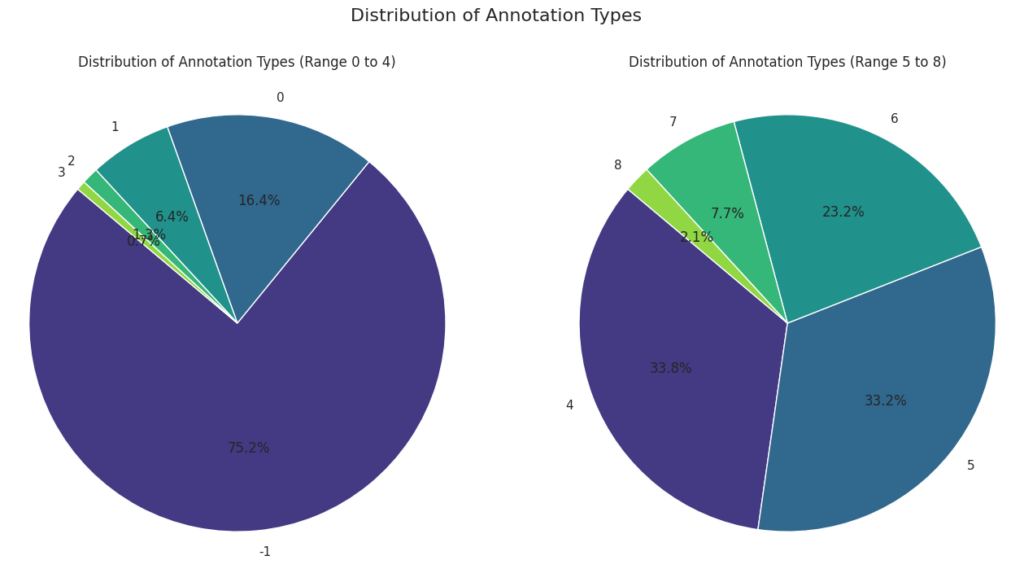
Analyze frequency and types of annotations (AnnoTypeCount)
Predictive Modeling:
Predict ToxicityInfo based on molecular features (SMILES, MolecularFormula):
Classify compounds as food-related using FoodRelated and other relevant features
Develop a model to predict PubMed_Count or Patent_Count based on compound properties.
Visualize the Distribution of Chemical Compounds based on PubMed and Patent Mention
Identifying the Most Common Molecular Formulas and SMILES Structures
Analyzing the Frequency and Types of Annotations Associated with Compounds.
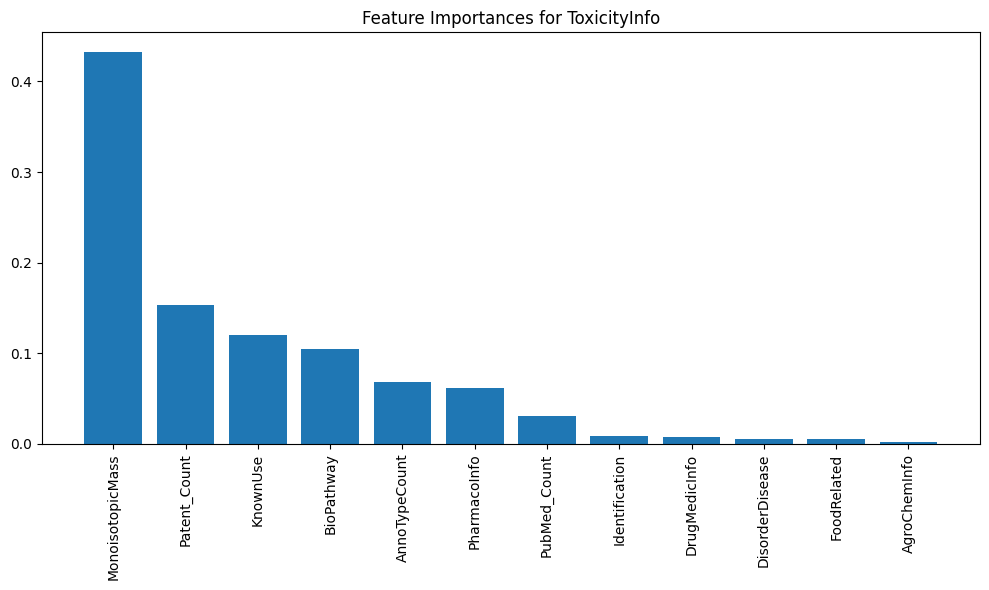
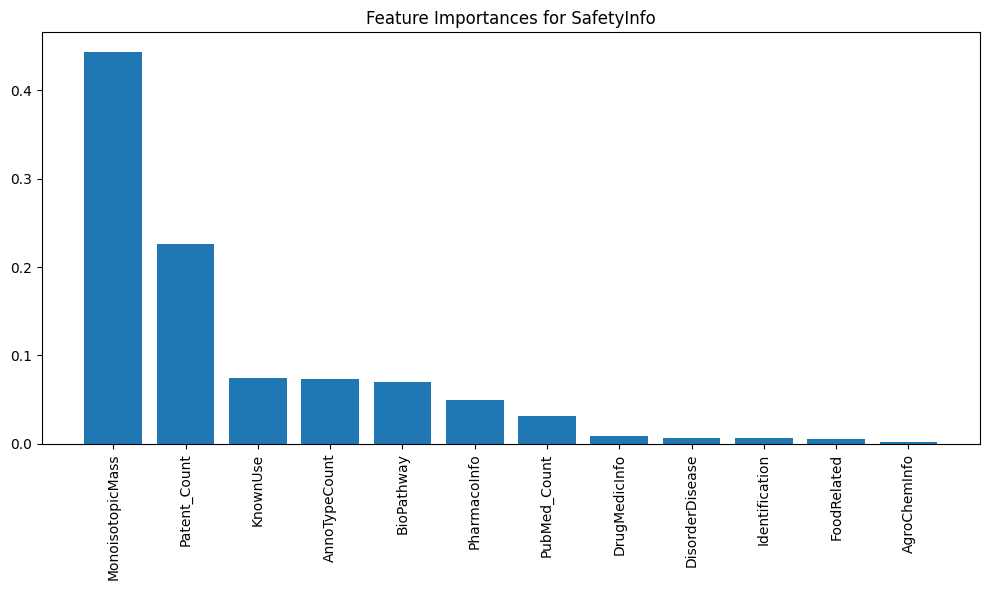
Feature Importance Analysis to determine which molecular properties are most predictive of SafetyInfo or ToxicityInfo.
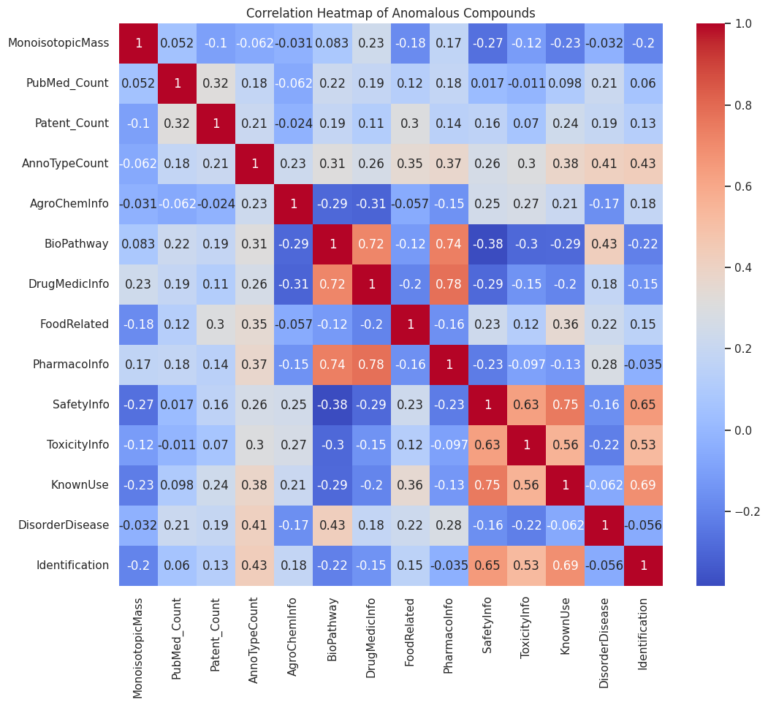
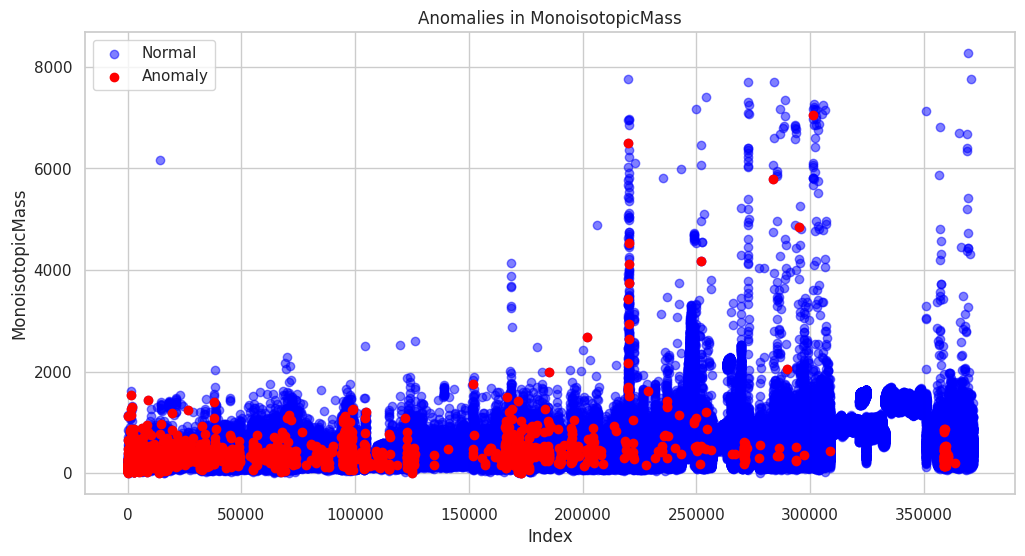
Anomaly Detection: Identify unusual compounds based on MonoisotopicMass or other properties.
Predictive Modeling: Predict ToxicityInfo based on molecular features (SMILES, MolecularFormula)
Through this project, I have honed my data science skills in several key areas:
- Data Preprocessing: I effectively handled missing values in the PubChemLite Compound Collection for Exposomics dataset. This involved identifying missing entries and applying appropriate techniques like imputation to fill them in a meaningful way.
- Feature Engineering: I explored the potential for creating new informative features from existing ones. This could involve techniques like representing molecular structures numerically or extracting additional information from textual data (e.g., from associated PubMed papers).
- Model Building: I investigated the development of models to predict target variables based on the rich set of features within the dataset. This might involve tasks like predicting toxicity based on molecular structure or classifying compounds as food-related based on their properties. Choosing the most suitable model type (classification or regression) would depend on the specific prediction goal.
- Evaluation: I planned to evaluate the performance of any models I develop using relevant metrics. This could involve metrics like accuracy, precision, recall, F1-score for classification tasks, or R-squared, Mean Absolute Error (MAE), and Mean Squared Error (MSE) for regression tasks.